CloudTrail
CloudTrail integrations as a source are supported in both the UI and the API.
Creating a CloudTrail integration
Create a self-hosted S3 data warehouse to connect Grepr to a CloudTrail S3 bucket. This is a one-time setup that allows Grepr to access an S3 bucket.
To set up a self-hosted S3 data warehouse, follow these steps:
- In the Grepr UI, navigate to the Data Warehouses section on the Integrations page.
- Add a new data warehouse and select S3 Data Warehouse as the type.
- Enter the CloudTrail S3 bucket details.
- Set up the necessary permissions for Grepr to access the S3 bucket.
- Add this bucket policy to the S3 bucket to allow Grepr to read the logs.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::992382778380:role/customer-role-{YOUR_ORG_NAME}"
},
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::{YOUR_BUCKET_NAME}"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::992382778380:role/customer-role-{YOUR_ORG_NAME}"
},
"Action": [
"s3:GetObject"
],
"Resource": "arn:aws:s3:::{YOUR_BUCKET_NAME}/*"
}
]
}- Add this key policy to the CloudTrail KMS key to allow Grepr to decrypt the logs.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::992382778380:role/customer-role-{YOUR_ORG_NAME}"
},
"Action": [
"kms:Decrypt",
"kms:DescribeKey"
],
"Resource": "*"
}
]
}Setting up the CloudTrail source
Once the self-hosted S3 data warehouse is set up, add CloudTrail as a source when creating a pipeline in the UI or via the API. Here is what the UI looks like:
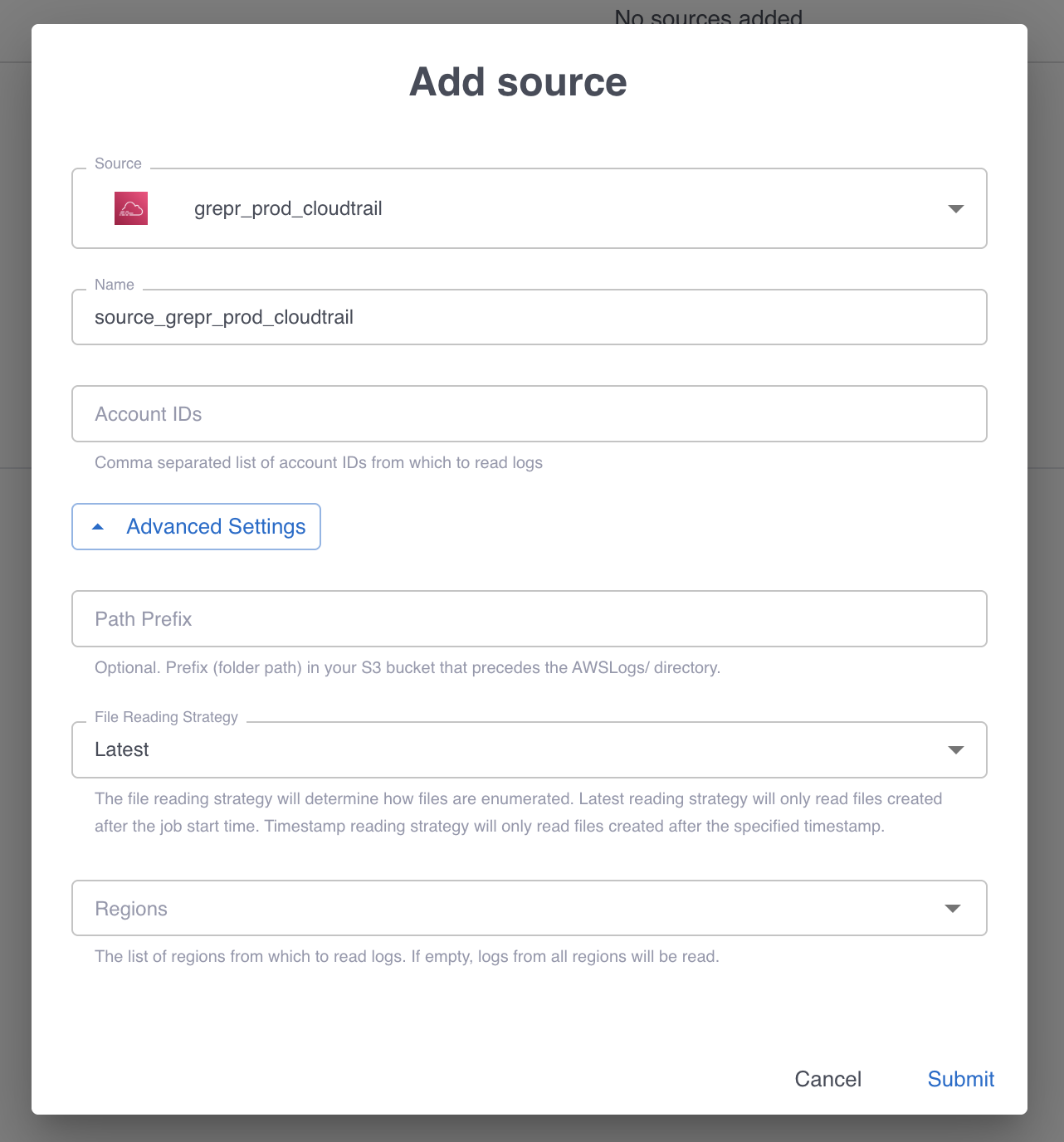
- Add every account ID to collect CloudTrail logs from. These are subfolders in the S3 bucket set up in the previous step. If adding more than one, they must be comma-separated.
- If the
AWSLogs/CloudTrail folder is not at the root of the S3 bucket, specify the prefix to the folder that contains it here. Otherwise, leave it empty. - Select a file reading strategy. The default is to read the latest files from the start of the job or choose the timestamp strategy to read files starting from a timestamp in the past (up to 2 days).
- Select the AWS Regions to collect CloudTrail logs from. If left empty / blank, all regions will be selected and read from by default.
Optimizing the Pipeline for CloudTrail
There are a few configuration areas to update to get the most out of the CloudTrail source:
- In the JSON Parser pipeline step, enable the
Preserve Json Content as Messageoption on the Json Processer tab. This enables similarity checks on the raw JSON of the log since there is no “message” field inside CloudTrail logs. Here is what this option looks like in the UI:
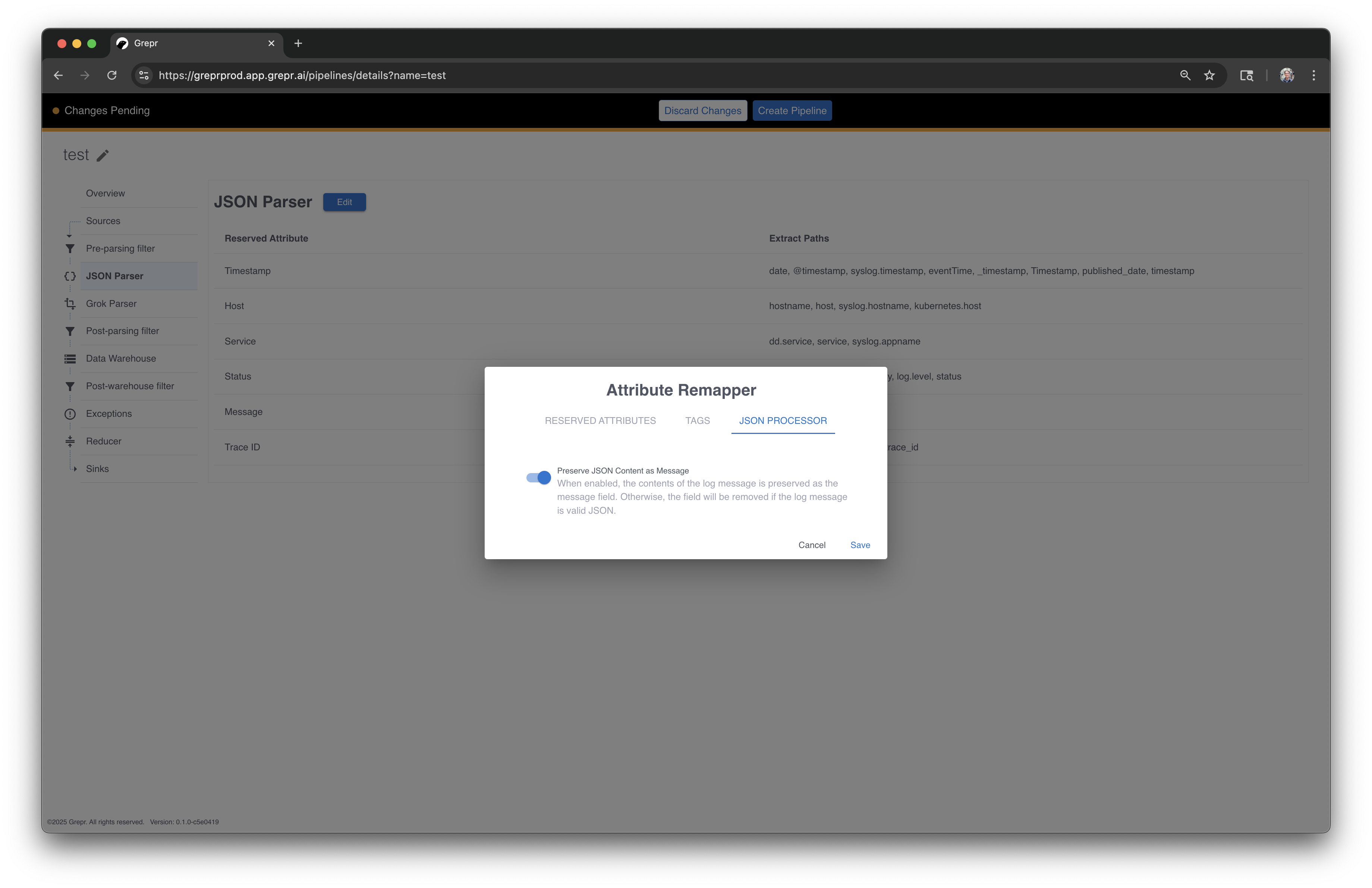
-
In the Reducer pipeline step, there are two configurations to set:
- Under the Grouping Configuration section, improve how the logs are partitioned by updating
the
Group-by valuesfield to:
service, @eventType, @eventCategory, @eventName, @sourceIPAddress, @recipientAccountId, @userIdentity.sessionContext.sessionIssuer.arn- Under the Mask Configuration section, enable the default
awsarnandawstokenmasks to boost reduction for AWS-specific datasets.
- Under the Grouping Configuration section, improve how the logs are partitioned by updating
the
Last updated on