Parse log messages to enrich log events with the Grok parser
You can use the Grok parser in the Grepr platform to parse and extract fields from semi-structured log messages, and then add those extracted fields as attributes, tags, or top-level fields in output log events. You can use the Grok parser in your pipelines to:
- Extract message context into trackable tags and attributes that can be referenced during incident investigations.
- Extract specific fields and add them as attributes or tags to ensure those fields are available in summarized events instead of being aggregated and masked by the reducer.
- Parse timestamps from log messages and set them as the event timestamp for tasks such as a time-series analysis.
- Convert unstructured text into structured fields that can be queried and analyzed efficiently.
To use the Grok parser, you define one or more Grok rules that specify how to parse log messages. Each rule consists of a name, a Grok pattern that describes what to look for in the log message, and optionally the fields to extract and how to transform those fields. See Grok rules overview.
You can add one or more Grok parsers to your pipelines in the Grepr UI or the REST API. To use Grok in the UI, see Configure the Grok parser in the pipelines UI.
To use Grok in the REST API, you define a GrokParser object and add it as a vertex in a Grepr job graph. See Create and manage jobs with the Grepr REST API
Grok rules overview
The syntax for a Grok rule is:
%{MATCHER:EXTRACTOR:TRANSFORMER}- The matcher describes what to look for when parsing. For example,
wordfor alphanumeric characters orintegerfor integer numbers. - The extractor names the destination for the parsed text. Extractors are optional when you define a Grok rule.
- A transformer, also referred to as a filter, converts the extracted values before adding to the output event. For example, convert a JSON string into a JSON object. Transformers are also optional when you define a Grok rule.
The following Grok rule:
- Matches a string of alphanumeric characters and extracts it as the
userfield. - Matches the next string of alphanumeric characters and extracts it as a tag named
lastnameby prependingtagsto the destination. - Matches a date in
MM/dd/yyyyformat, extracts it as thedatefield, and converts it to a timestamp. - Matches an IPv4 address and extracts it as the
ipfield.
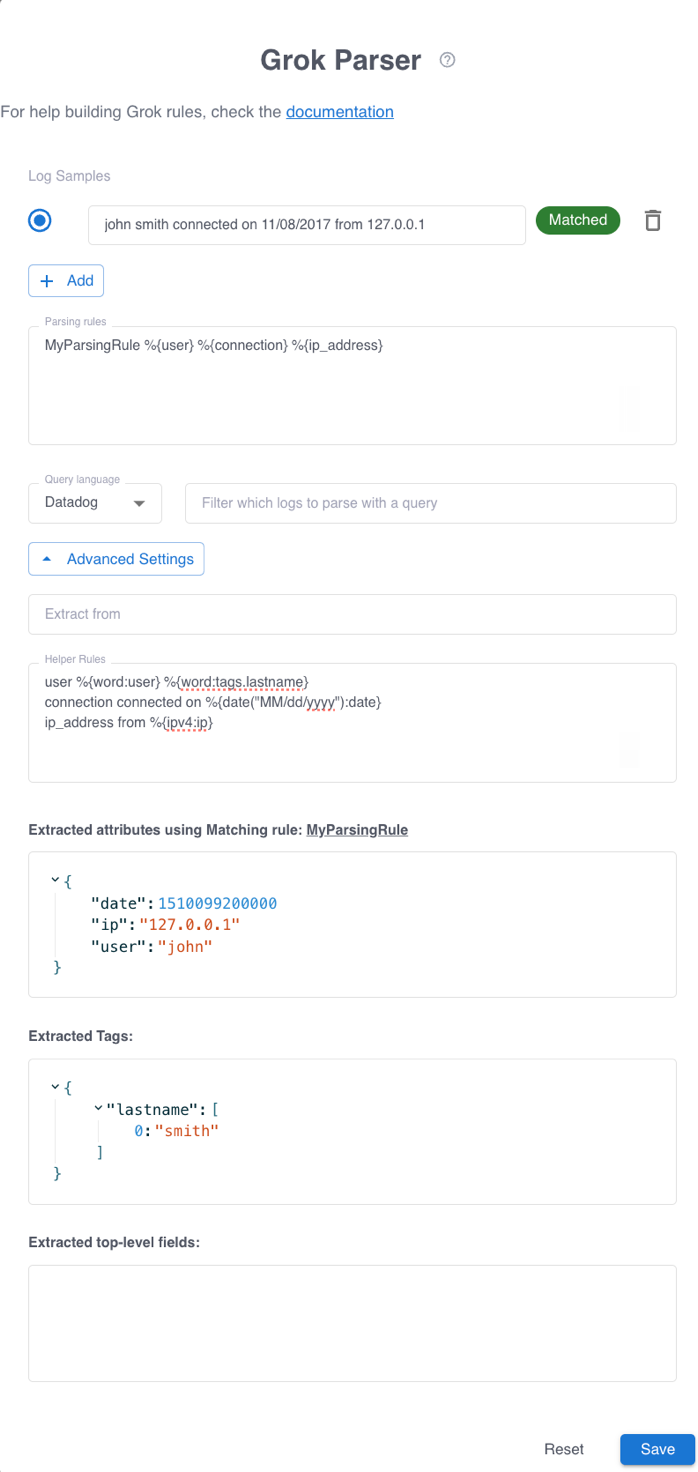
MyParsingRule %{word:user} %{word:tags.lastname} connected on %{date("MM/dd/yyyy"):date} from %{ipv4:ip}Applying this rule to the log message:
john smith connected on 11/08/2017 from 127.0.0.1Results in the following enriched log event:
{
"message": "john smith connected on 11/08/2017 from 127.0.0.1",
"attributes": {
"user": "john",
"date": 1510099200000,
"ip": "127.0.0.1"
},
"tags": [
"lastname:smith"
]
}All extracted fields are added to the attributes of the output log event, with the following exceptions:
- If you prefix the extractor with
tags., the extracted field is added to the tags of the log event. - If the extractor is
severity, the extracted field is used to set a top-levelseverityfield in the output log event. - If the extractor is
eventTimestamp, the extracted field is used to set a top-leveltimestampfield in the output log event.
For example:
%{word:user} # Adds to attributes: {"user": "john"}
%{word:tags.environment} # Adds to tags: ["environment:production"]
%{word:severity} # Sets log severity level
%{integer:eventTimestamp} # Sets log event timestamp in millisecondsCreate multiple parsing rules
You can define multiple Grok parsing rules, each with a unique name. The parser tries each rule in order until it finds a match. This approach is useful when different types of log events might require different parsing patterns.
Example with multiple rules:
LoginRule %{word:user} logged in from %{ipv4:ip}
LogoutRule %{word:user} logged out at %{date("HH:mm:ss"):time}
ErrorRule ERROR: %{data:error_message}You can also define helper rules that act as reusable components in your main parsing rules. Helper rules don’t parse log messages directly but provide building blocks for your main rules.
Using the previous Grok rule as an example:
MyParsingRule %{word:user} %{word:tags.lastname} connected on %{date("MM/dd/yyyy"):date} from %{ipv4:ip}The following shows how this rule can be rewritten using helper rules:
MyParsingRule %{user} %{connection} %{ip_address}
# Helper rules
user %{word:user} %{word:tags.lastname}
connection connected on %{date("MM/dd/yyyy"):date}
ip_address from %{ipv4:ip}Supported matchers
The Grepr Grok parser supports all matchers from Logstash plus additional Datadog-compatible matchers.
For a reference to all supported Logstash matchers, including descriptions and examples, see The Grepr Grok parser: Logstash matchers.
For a reference to all supported Datadog-compatible matchers, including descriptions and examples, see The Grepr Grok parser: Datadog-compatible matchers.
Supported transformers
For a reference to all supported Grok transformers, including descriptions and examples, see The Grepr Grok parser: Supported transformers.
Configure the Grok parser in the pipelines UI
You can configure Grok parser rules in the Grepr UI when creating or editing a pipeline. To add a rule for the Grok parser:
-
On the details page for your pipeline, in the left-hand navigation menu, click Grok Parser to open the Grok Parsing Rules pane.
-
Click Add to open the Grok Parser dialog.
-
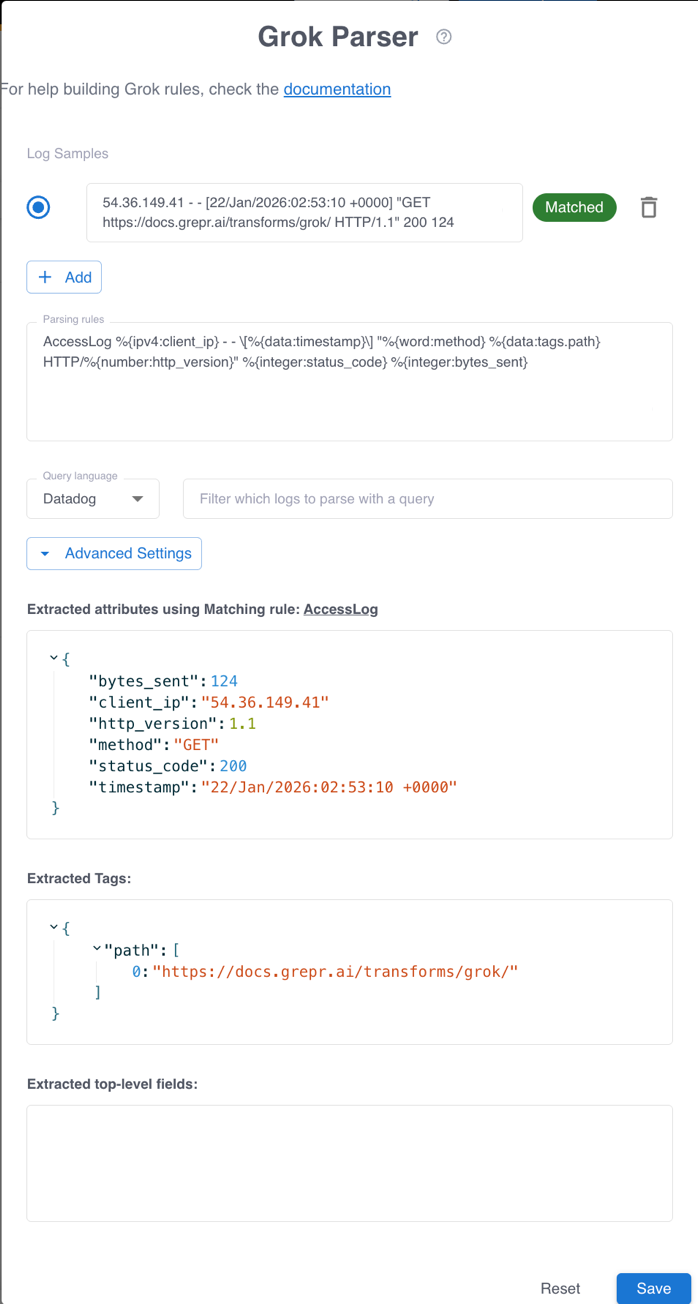
In the Message field, enter a sample log message that you want to parse.
-
(Optional) To add more sample log messages, click + Add and enter additional log messages.
-
In the Parsing rules text box, enter your Grok parsing rules. Each rule must be on a separate line. As you type, the parser validates your rules against the log samples you provided. The validation results appear in the Extracted attributes using Matching rule field.
-
(Optional) To filter which log events the parser processes:
- In the Query language menu, select a query syntax.
- In the Filter which logs to parse with a query field, enter your filter query. Only logs that match the query are parsed. If you leave this field empty, all logs are parsed. To learn about supported query syntaxes, see Query log data in the Grepr data lake.
-
(Optional) To configure advanced settings, click Advanced Settings.
- By default, the Grok parser extracts data from the
messagefield in the input log events. To instead specify an attribute containing the message or other unstructured text, enter the attribute name in the Extract from field. - To configure Grok patterns that can be referenced in multiple parsing rules, enter them in the Helper Rules text box. Enter each pattern on a separate line.
- By default, the Grok parser extracts data from the
-
After you’ve reviewed and validated the results in Extracted attributes using Matching rule:, Extracted Tags:, and Extracted top-level fields:, click Save.
-
To add another Grok parser rule, click Add.
Best practices
Follow these best practices when using the Grok parser:
-
Test with real log samples: Always validate your parsing rules with actual log messages from your system before deploying to production. Use the log samples feature in the Grok Parser dialog to test your patterns.
-
Start with simple patterns: Build complex patterns incrementally. Start with a simple rule that matches the most important fields, then add more fields as needed.
-
Use helper rules for reusable patterns: If you have complex patterns that appear multiple times, define them as helper rules. This approach makes your parsing rules more maintainable and easier to read.
-
Be specific with matchers: Use the most specific matcher possible. For example, use
ipv4instead ofdatawhen matching IP addresses. Specific matchers provide better validation and type conversion. -
Use a filter to specify which logs to parse: When only a subset of log messages requires parsing, you can limit which log events are processed with the Filter which logs to parse with a query field in the pipelines UI or the
GrokParser.predicateobject in the REST API. Avoiding unnecessary parsing attempts improves performance and reduces cost. -
Use appropriate transformers: Apply transformers to convert extracted values to the correct type. For example, use
::integerfor numeric fields that should be integers, not strings. -
Order rules from specific to general: When defining multiple parsing rules, place more specific patterns first. The parser tries each rule in order and uses the first match.
-
Avoid greedy matchers at the start: The
datamatcher is greedy and matches everything. Avoid using it at the beginning of a pattern, as it may match more than intended. -
Extract timestamps: If your logs contain timestamps, extract them using the
datematcher and set them aseventTimestampfor accurate time-series analysis. -
Extract severity levels: Extract log severity levels (INFO, WARN, ERROR) and set them as the
severityfield to enable filtering and alerting based on log level.
Limitations
The Grok parser has the following limitations:
-
Performance impact: Complex Grok patterns with many rules can impact processing performance. Test your patterns with representative log volumes to ensure acceptable performance.
-
Regex complexity: Very complex regular expressions in
regex()matchers can be slow to evaluate. Keep regex patterns as simple as possible. -
No backtracking: Once a parsing rule matches a log message, the parser doesn’t try other rules. Ensure your rules are ordered correctly.
-
Character encoding: The Grok parser expects UTF-8 encoded log messages. Other character encodings may cause parsing errors.
-
Timezone handling: When using the
datematcher without a timezone parameter, the parser assumes UTC. Always specify the timezone if your logs use a different timezone.